Alex Net
# 研究背景
在该篇文献出现之前(2012),大多数目标识别方法都是基于机器学习的方法,例如决策树和SVM等。这些方法在一些小规模的数据集上,如MNIST数字识别,已经取得十分优秀的准确率,甚至接近人类水平。但是在真实环境下的目标对象往往是具备丰富、复杂和变化性大的特性,以往的典型方法难以在真实环境下有较好的表现。因此为了提高目标识别的性能,需要一个学习能力更强大的模型来支持。在模型上,卷积神经网络是一个优秀的神经网络架构,它的能力可以通过改变其广度和深度来控制,对于目标识别具有强大的潜力,特别是在图像方面,其相比于之前的前馈神经网络而言,其神经元连接和参数较少,因此它更容易训练。在数据上,为了能够让模型在真实环境中应用,需要更丰富的训练数据集,好在随着LabelME和ImageNet的大规模数据集出现,使得卷积神经网络模型能够从大规模数据集中对学习到更深层的知识表达,有利于目标识别在复杂环境下的性能。


# 问题描述
虽然CNN具备强大的图像识别学习能力,但是模型训练过程中还是存在许多困难。首先是网络结构,神经网络的训练难度随着层数的增加而难度,在梯度更新上可能会存在梯度消失,导致网络无法更新;接着是过拟合问题,CNN上的训练可能会导致过拟合,需要一个有效的技术来防止过拟合;然后是训练时间问题,网络结构越复杂,层数越深,训练所需的时间就越久,这对于计算机硬件的计算速度和内存都是巨大的压力和挑战;最后是一些超参数的调整,例如选择恰当的学习率以如何防止陷入局部最优。
# 解决方案
# ReLU引入
Alex Net为解决网络训练梯度更新缓慢,帮助网络加速收敛,首次采用ReLU(修正非线性单元)作为激活函数。
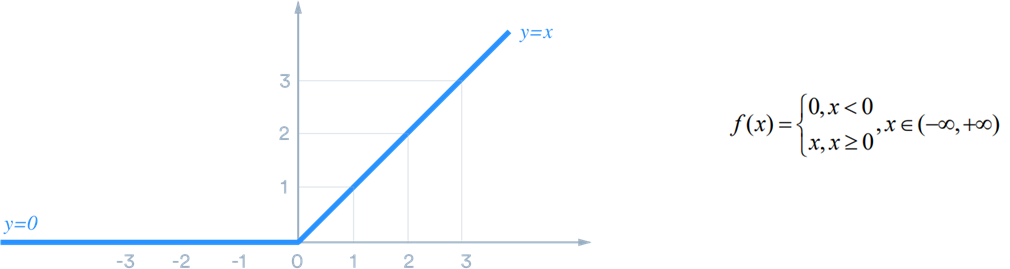
作者使用两个相同的四层卷积神经网络对CIFAR-10数据集进行测试,一个网络使用ReLU激活函数,另一个使用tanh激活函数,实验结果表明,采用ReLU的深度卷积神经网络的收敛速度,要比之前使用tanh快。
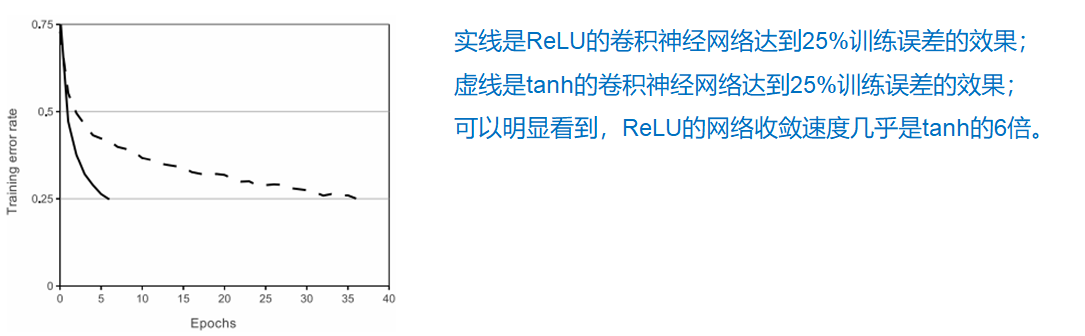
# GPU训练
网络结构越复杂,对于训练硬件设备要求越高。一方面是训练时间问题,由于网络庞大的参数学习,单纯使用CPU进行矩阵运算则要花费大量的时间,所以需要具有强大矩阵运算能力的GPU来替代。另一方面是内存问题,一块GPU内存有限,无法将整个网络载入,因此需要多块GPU组合,配合训练。
该文献中,作者使用两块GTX 580 GPU 3GB内存的显卡来进行训练。采用GPU并行方案,基本行每个GPU放置一半的神经元,此外还有一个额外的技巧:只要特定的层上进行GPU的通信。
# 局部响应归一化(LNR)
该文献发现,在卷积和池化后,进行局部响应归一化有助于泛化。其公式如下:

举例:
i=10,N=96,n=4,那么第i=10个卷积核所在(x,y)处的特征点(a)的局部响应归一化过程为:用(a)的值除以第8,9,10,11,12在(x,y)位置特征值的平方和
传送门:https://www.jianshu.com/p/c014f81242e7
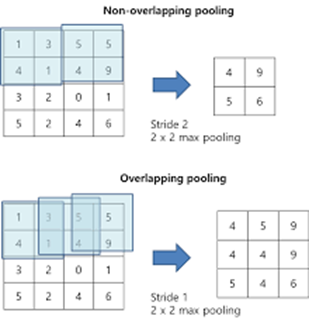
# 重叠池化
该文献指出,若在训练过程中采用重叠池化技巧,能使得模型更难过拟合。
所谓重叠池化,即相邻池化窗口之间会有重叠区域。如果定义池化窗口的大小为z,定义两个相邻池化窗口的水平/竖直位移的步长为s。若s = z,那么是传统的非重叠池化,若s<z,就可以得到重叠池化。
# 减少过拟合
为了避免神经网络出现过拟合,作者采用两种方式来解决过拟合问题。第一是对数据增强,第二是引用Dropout算法。
# 数据增强
第一种对数据增强的方式是对原始图像进行裁决和几何变换,对训练样本扩增。
训练:对原始图像重采样到256×256,然后随机裁剪出224×244的图像,这样方式横向有64(256-244)次,竖向也是64,再加上左右和上下翻转,相当于把训练数据集扩大了64 × 64 × 2 = 2028倍。
预测:选择一张图片的四个角的224×244,加上中间的224×244,然后左右翻转,共一10张图片的平均值做为结果。
第二种对数据增强的方法是改变训练图像的RGB的强度。
- 对训练图片进行PCA变换,然后对在主成分上加一个高斯噪声干扰。
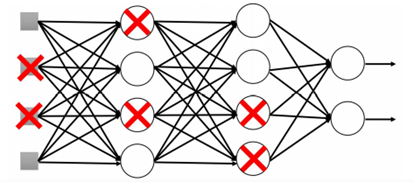
# Dropout
Dropout会以一定概率P(比如0.5)将隐含层神经元输入和输出设置为0。这些被选中的神经元不再进行前向传播和反向传播,但是它的权重会保留下来,因此每次输入x都将会是一个不同的神经网络。这个技术减少复杂神经元的互适应,避免模型过拟合。
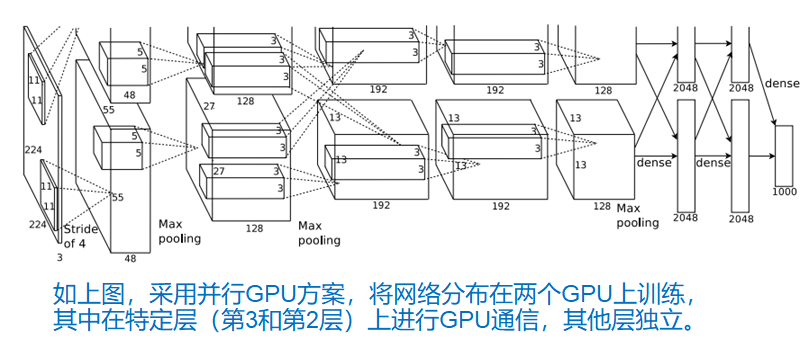
# 整体网络结构
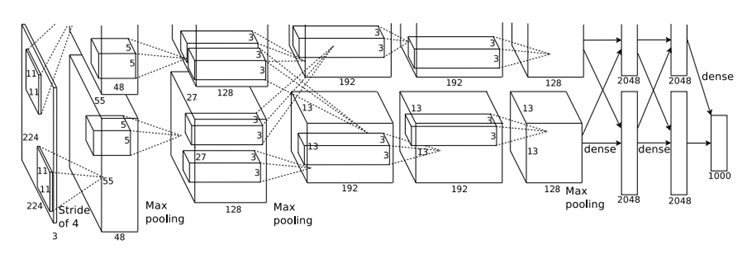
最终整个CNN架构如上图所示,Alex Net一共8层,前5层是卷积层,后3层是全连接层,最后一层是1000维softmax的输出。
第1卷积层:96个11×11的卷积核对224×224×3的输入图像滤波,步长为4,经过LNR和Max Overlaping Pooling(3×3,步长2)后输出27×27×96的特征图;
第2卷积层:256个5×5的卷积核对第1卷积层输出的27×27×96的特征图滤波,步长为1,经过LNR和Max Overlaping Pooling(3×3,步长2)后输出13×13×256的特征图;
第3卷积层:384个3×3的卷积核对第2层卷积层输出的13×13×256的特征图滤波,步长为1,不经过LNR和Max Pooling,然后输出13×13×384的特征图。
第4卷积层:384个3×3的卷积核对第3层卷积层输出的13×13×384的特征图滤波,步长为1,不经过LNR和Max Pooling,然后输出13×13×384的特征图。
第5卷积层:256个3×3的卷积核对第4层卷积层输出的13×13×384的特征图滤波,步长为1,经过LNR和Max Overlaping Pooling(3×3,步长2) ,然后输出6×6×256的特征图。
第6,7和8全连接层:将第5卷积层输出6×6×256展开为9126单元,进入两层4096单元的全连接层,使用Dropout策略,然后softmax输出1000类。
# 实验分析
# 学习参数细节

# ILSVRC结果
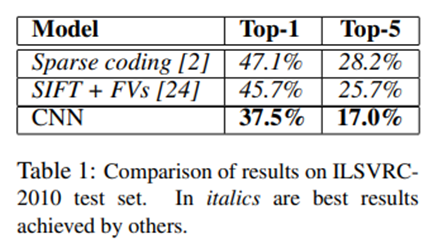
作者使用模型在ILSVRC-2010测试集取得了top-1 37.5%和top-5 17%的错误率。相比较以往的方式有显著的突破。
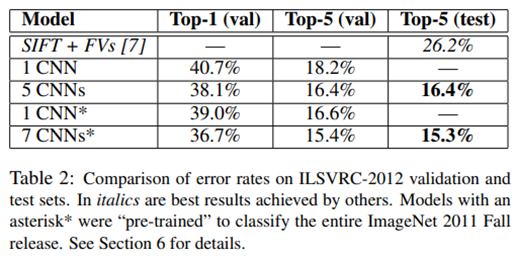
作者接着用模型参加ILSVRC-2012竞赛。本文使用的模型取得top-1 40.7%和top-5 18.2%的错误率;五个类似的CNN模型平均后取得top-1 40.7%和top-5 16.4%的错误率,可以说是历史性的突破。
Top-1 是预测结果概率排名第1的类别与实际结相符的准确率;
Top-5 是预测结果概率排名前5的类别包含实际结果的准确率。
# 定性分析

右侧图3展示了网络第一卷积层的11×11×3的96个卷积核的可视化效果。
这96个卷积核学习到表征图像频率选择、方向选择和色彩等特征。
前48个卷积核是在GPU1上得到,其特征与颜色无关;
后48个卷积核是在GPU2上得到,其主要是针对颜色特征。

上图左侧是作者对8张测试图像计算它们在top-5预测结果。每张图下面是图像的正确标签,下方红色是正确标签的概率。可以看到对于一些图片,即使不在图像中心也可以识别,例如第1张的mite,同时大多数top-5标签都是相对合理。
上图右侧是比较在卷积层输出4096维特征,在空间上相似程度。作者使用欧式距离作为相似性度量标准。第1列的5张是测试图像,剩下的列是训练图像。这些训练图像的特征向量与测试图像有最小欧式距离。
# 总结与展望
# 总结
Alex Net通过在ILSRVC-2012竞赛上,证明了大型卷积神经网络的强大能力,取得了历史性突破结果(top-1 38.1% top-5 16.4%)。
同时,作者也验证了深度的重要性,若移除一个卷积层,会降低网络的性能。例如移除中间任意一个卷积层,会引起网络损失大约2%的top-1性能。
# 展望
- 采用无监督的预训练
- 在拥有更新信息的视频序列的时序中数据应用大型卷积神经网络