Very Deep Convolutional Networks for Large-Scale Image Recognition
# 研究背景
卷积神经网络(ConvNet)在近年来在大规模图像识别上取得巨大成功,这得益于三方面的进步,一是大规模公开数据集,例如ImageNet;二是高性能计算系统,例如GPU和大规模分布式集群;三是神经网络的深度拓展。但是目前对卷积网络的结构设计缺乏一个可参考性指导,大多数研究人员主要关注于深度,忽视结构。因此该片文献提出了一个能作为参考标准的ConvNet结构,基于这类型结构,作者在ILSVRC分类和定位任务取得最佳的准确性,并验证其也适用于其他的图像识别数据集。
# 问题描述
随着ConvNet在计算机视觉上的广泛应用,为了取得更好的精度,研究人员开始不断改进最初的架构,也就是在ILSVRC-2012竞赛上大放光彩的Alex Net。在ILSVRC-2013竞赛上,Sermanet等认为一方面使用更小的感受野和更小的步长能取得更好的精度,另一方面考虑多尺度的密集地训练和测试,也能提高精度。该篇文献在网络深度上,通过使用较小感受野(3×3)卷积层来稳定增加网络的深度,在网络结构上,通过连续的(3×3)卷积层堆叠来替代原始的(5×5)和(7×7)的卷积层。在各项实验中,验证作者提出的ConvNet结构的可靠性,在各方面都超越了以往设计的网络,仅有GoogleNet能相媲美。
# 解决方案
# VGGNet的架构设计
该篇文献提出的网络(一般称为VGGNet),是由一堆感受野为(3×3)或(1×1),步长为1的卷积层、(2×2)大小、步长为1的池化层和三个全连接层组成,所有隐含层激活函数选用ReLU。作者根据上面的基础设置,配置了以下(A-E)五个不同深度的ConvNet,从网络A的11层到E的19层,卷积核个数从第一层的64开始,每经过最大池化层之后增加2倍,直到512。
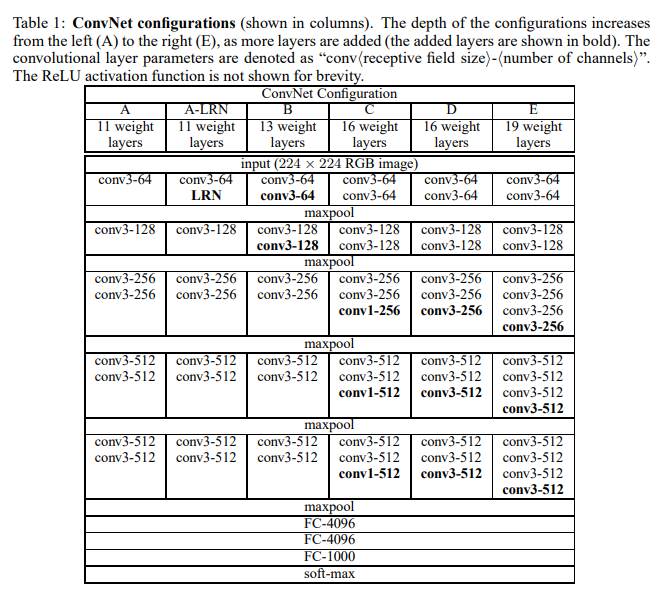
表1:ConvNet配置(以列显示)。随着更多的层被添加,配置的深度从左(A)增加到右(E)(添加的层以粗体显示)。卷积层参数表示为“conv⟨感受野大小⟩-通道数⟩”。为了简洁起见,不显示ReLU激活功能。
A-E网络的参数信息如下表所示。

表2:参数数量(百万级别)
# VGGNet的创新点
相比较之前的Alex Net等,它们的网络在第一卷层使用相对较大的感受野(11×11)和步长(4),而该篇文献中网络仅使用非常小的感受野(3×3)和步长(1),这样的设计有以下几点好处:
- 两个3×3卷积层堆叠(没有空间池化),能相当于5×5的有效感受野,三个堆叠有7×7的有效感受野。两个或三个卷积层堆叠能通过更多的非线性激活函数,而不是单一,这能使决策函数更加具有判别性。
- 减少参数的数量。假设三层3×3卷积堆叠的输入和输出有个通道,堆叠卷积层的参数为个权重;同时,单个7×7卷积层将需要个参数,即参数多81%。
- 添加1×1卷积层(配置C),能增加决策函数非线性而不影响卷积层的感受野。在方法在“Network in Network”架构中已经得到了使用。
# 训练和测试
关于训练和测试的通俗理解,可以参考:
- 传送门1:https://blog.csdn.net/weixin_43624538/article/details/84563093
- 传送门2:https://zhuanlan.zhihu.com/p/42233779
# 训练
VGGNet的训练参数参考AlexNet,配置参数如下:
- 优化方法(optimize):具有动量的小批量梯度下降
- 学习率(learning rate):0.01
- 动量(momentum):0.9
- 批次大小(batch size):256
- 迭代次数(eopch):74
- 丢弃正则化(Dropout rate):0.5
- L2正则化:通过权重衰减(L2惩罚因子设定为5·10^{-4})
尽管VGGNet的网络参数比AlexNet要大,但是网络使用跟小的epoch就可以收敛,这是由于(a)由更大的深度和更小的卷积滤波器尺寸引起的隐式正则化,(b)某些层的预初始化。
网络的初始化 网络的初始化是十分重要的,不好的初始化可能会导致网络梯度不稳定,阻碍学习进度。作者为了更好的初始化,采用两种方法,一是训练浅层网络(配置A),然后当训练更深的网络时,使用已经训练的浅层网络(配置A)的层来初始化深层网络的四个卷积层和最后三个全连接层(中间层被随机初始化)。对于随机初始化,采用从均值为0和方差为10^{−2}的正态分布中采样权重。二是作者发现可以通过使用Glorot&Bengio(2010)的随机初始化程序来初始化权重,就不再需要预训练。
训练图像大小 首先将图片同质化的缩放,然后选取一个固定最小边S(训练尺度),然后在S上截取大小为224×224的区域。
同质化的缩放(isotropically rescaled): 沿宽度和高度应用相同的缩放系数,因此图像不会沿一个轴变形,所以S取最小边
S 的选取有两种方式:
第一种:固定S的方式,选取固定的S,例如256和384。对于一个给定的神经网络配置,首先训练 S=256。为了加速训练 S=384 的网络,会使用预训练的 S=256 网络的权重来初始化参数,然后使用更好的初始化学习速率 1e-3
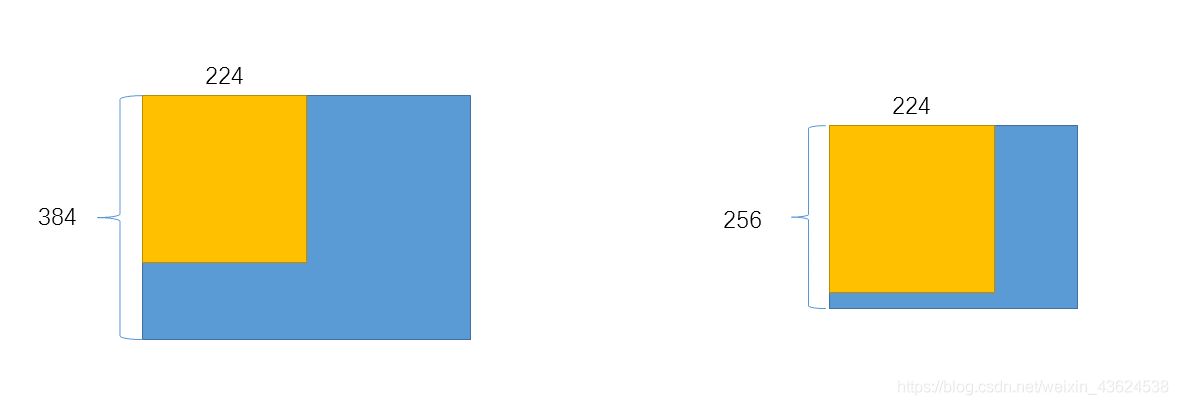
第二种:设置S为多尺度,每次训练图片,都通过从一确定的范围 (通常值为 、)随机采样一个 S ,使用此 S 来缩放图片。因为图片中的物体有不同的尺寸,通过 S 多尺度,这样的情况就被考虑了进去。
因为速度的原因,论文中训练多尺寸模型时,是通过微调( fine-tuning)具有相同配置的,固定尺寸 S=384 的预训练模型的所有层。
# 测试
在测试时,首先将图像同质化缩放到预设最小图像边Q(测试尺度),Q不必和S相等,接着将网络的全连接层替换为卷积层(第一个全连接转换为7X7的卷积层,后两个全连接网络转换为1X1的卷积网络),整个网络由于没有了全连接层,网络中间的feature map不会固定,所以网络对任意大小的输入都可以处理。
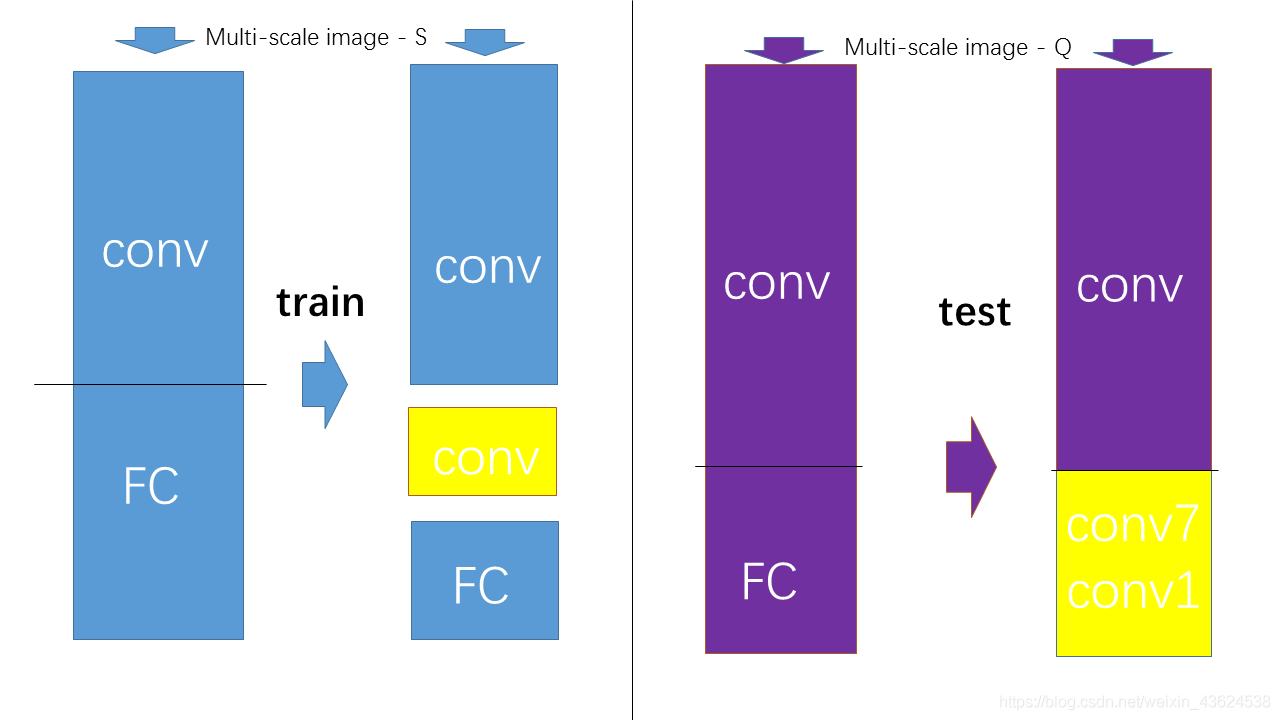
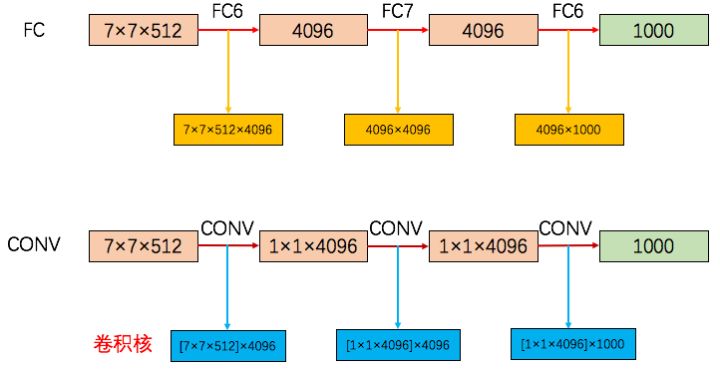
在上图中,以第一个全连接层转卷积层为例,FC6的输入是 7×7×512,输出是4096(也可以看做 1×1×4096),那么就要对输入在尺寸上(宽高)降维(从7×7 讲到 1×1)和深度(channel 或者 depth)升维(从512 升到4096。把7×7降到1×1,使用大小为 7×7的卷积核就好了,卷积核个数设置为4096,即卷积核为7×7×4096(图中的[7×7×512]×4096 表示有 4096 个 [7×7×512] 这样的卷积核,7×7×4096 是简写形式忽略了输入的深度),经过对输入卷积就得到了最终的 1×1×4096 大小的 feature map。
测试得到结果是一个类别分数图像,这个图像的通道数等于需要分类的类别的数量,最终为了获得相对于图像类别的固定尺寸向量,类分数图要通过空间平均(池化和)。
(假设输入的图是384x384x3,得到最终输出为 6x6x1000 的 feature map,进行空间平均,取池化和,得到1x1x1000,再进行softmax)
VGGNet通过水平翻转来增强图像测试集,将原始图像和翻转图像的类分数图进行softmax得到类后验平均化以获得图像的最终分数(正图和反图都是这个类,那就是这个类)。
由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。虽然作者认为在实践中,多裁剪图像的计算时间增加并不足以证明准确性的潜在收益,但作为参考,还是在每个尺度使用50个裁剪图像(5×5规则网格,2次翻转)评估了我们的网络,在3个尺度上总共150个裁剪图像。
关于密集评估(dense)和多裁剪评估
可参考传送门:https://www.zhihu.com/question/270988169
# 实验分析
作者将文献中提出的各种ConvNet结构(表1,配置A-E)在ILSVRC-2012数据集上进行实验,数据集包含1000个类别,并分为三组:训练集(130万),验证集(5万)和测试集(10万)。使用两个评估分类性能的指标:top-1和top-5错误率,前者是多分类误差,后者是图像真实类别在前5个预测类别之外的比例。
# 单尺度评估
评估单个VGGNet模型在单尺度上的性能,对测试尺寸设置如下:对于固定S,;对于动态,。结果如表3所示。
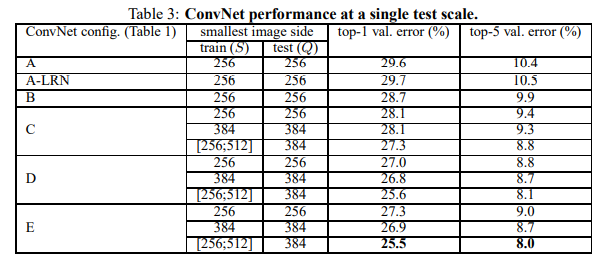
首先,对比(A-LRN)和(A),可以看到局部响应归一化没有改善模型,因此,较深的结构(B-E)中不采用局部响应归一化。其次,可以看到分类的误差随网络的深度的增加而减少。接着对比B和C的结果,表明额外的非线性能有助于决策函数(C比B多3个1×1的卷积层),对比C和D的结果,说明3×3的感受野的卷积能捕获空间上下文,比1×1好。同时作者还对比与网络B相同层数,但使用5×5感受野的卷积,结果在top-1的错误率上高7%,这证实了具有小滤波器的深层网络优于具有较大滤波器的浅层网络。最后来对比尺寸抖动和固定尺寸,可以看到尺寸抖动效果更好,这也证实了尺寸抖动能有助于捕获多尺度图像统计。
# 多尺度评估
评估单个VGGNet模型在多尺度上的性能,即一张测试图像对应于不同的Q值,然后对所得到的类别后验进行平均。对测试尺寸设置如下:对于固定的S,;对于动态,。结果如表4所示。
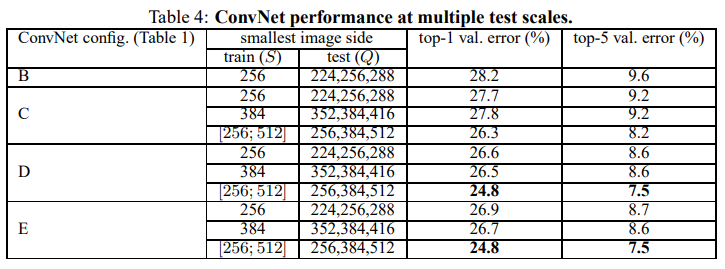
表4中给出的结果表明,测试时的尺度抖动导致了更好的性能(与在单一尺度上相同模型的评估相比,如表3所示)。
# 多裁剪图像评估
评估密集预测和多裁剪图像预测的性能,也通过平均两者在softmax输出来评估这两个方法的互补性。结果如表5所示。
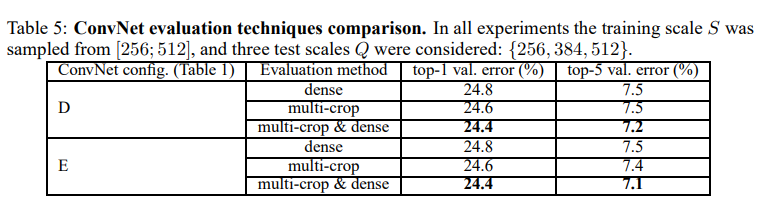
可以看出,使用多裁剪图像表现比密集评估略好,而且这两种方法确实是互补的,因为它们的组合优于其中的每一种。
多裁剪图像通俗理解,参考:https://www.zhihu.com/question/270988169
# 卷积网络融合
在这部分实验中,通过平均模型输出的softmax,作为融合模型,来评估模型的互补性。结果如表6所示。

仅考虑表现最好的多尺度模型(D和E),它使用密集评估将测试误差降低到7.0%,使用密集评估和多裁剪图像评估将测试误差降低到6.8%。
# 与最新技术比较
最后,与最新技术比较,结果如表7所示。
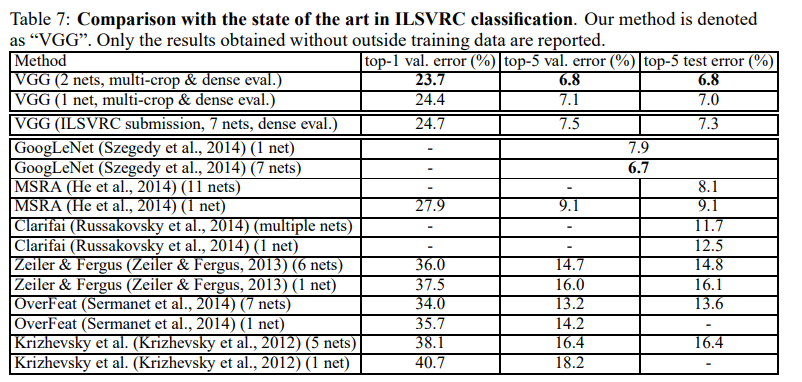
作者的VGGNet使用2个模型的组合将错误率降低到6.8%。同时可以看到VGG模型显著优于前一代的模型,在ILSVRC-2012和ILSVRC-2013竞赛中取得了最好的结果。结果对于分类任务获胜者(GoogLeNet具有6.7%的错误率)也具有竞争力,并且大大优于ILSVRC-2013获胜者(Clarifai)。
# 总结
该篇文献提出的VGGNet模型一方面证实表明深度有利于分类(深度从11-19),另一方面利用3×3卷积层的堆叠替换5×5和7×7的卷积,不仅减少了参数量,还提高了准确率,最后在训练和测试上提出多尺度和密集预测的方式,也有效提高的模型的精度。在文献附录中也对其他任务的数据集上进行实验,表明该模型也能很好泛化到其他图像应用领域。