Going Deeper with Convolutions
# 研究背景
由于深度卷积神经网络的发展,图像的目标分类和检测方面都得到显著提高。这些进步益于硬件的高速发展、大规模数据集形成,最重要的是对网络结构设计的创新。另一方面随着移动和嵌入式设备的推动,对于深度卷积神经网络的效率的要求也越高,尤其是在耗时和内存使用上。在该篇文献中,作者设计一个高效的深度卷积神经网络架构,代号为Inception,基于Inception模块构建的神经网络称为GoogLeNet。它的参数仅有AlxeNet的1/12,但是其结果优于AlexNet,并在ILSVRC2014分类竞赛上取得冠军(top-5 6.67%)。
# 问题描述
目前提高深度神经网络性能最直接的方式是增加网络的深度和宽度。但是这个方案有两个主要的问题,一是更深和更宽的网络尺寸通常意味着更多的参数,训练的负担相对较大。二是容易过拟合,特别在训练集的标注样本有限的情况下。**解决这两个问题的一个基本理论是引入稀疏性并将全连接层替换为稀疏全连接层,甚至是卷积层。**作者基于对理论的思考,综合实践的情况,提出Inception架构,试图近似表达网络的稀疏结构。虽然不太能理论证明Inception模块是否能够体现出稀疏性,但是在各项实验的结果分析可知,它能取得目前最好的成绩,说明它在一定程度上是具有效果的。
# 解决方案
# Inception模块
Inception模块的目的是近似卷积神经网络的最优稀疏结构,并利用密集、易实现的组件来假设逼近。
作者首先提出基础的Inception (a)模块,如下图所示。
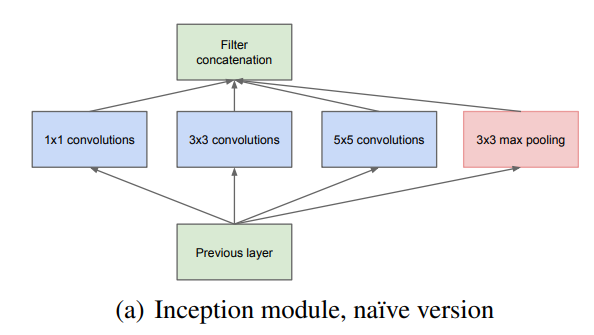
对基础的Inceptiom模块理解是,对输入的特征图复制4份,对它们分别使用不同数量的1×1、3×3和5×5的卷积核,以及3×3的最大池化提取不同尺度的特征,设定卷积步长为1,same padding,保证输出的特征图尺寸一致,最后其拼接在一起(不同尺度的特征融合)。
当特征图的维数增大时,使用5×5的卷积核会带来巨大的计算量,因为该篇文献参考NIN的思路,采用1×1的卷积核来降维。于是提出改进后的Inception(b)模块,如下图所示。
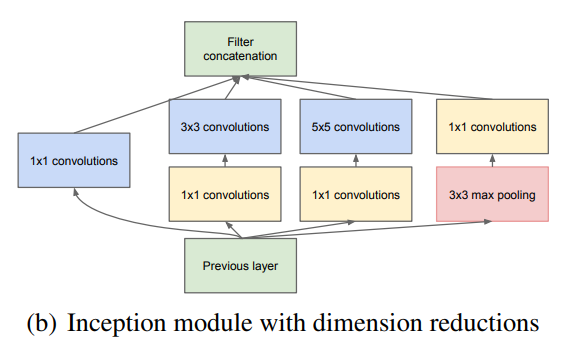
图中黄色的1×1卷积核用于降维。在进行3×3和5×5卷积之前,先采用1×1卷积减少特征图的通道。此外1×1卷积核也能增加非线性。
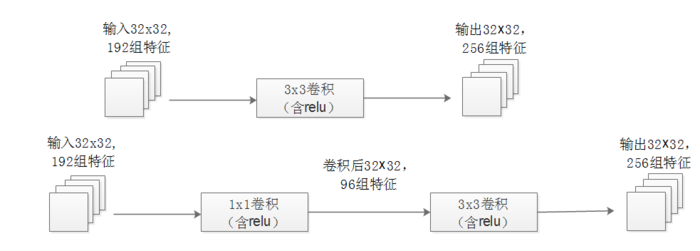
下图举例,同样是输入一组有192个特征、32x32大小,输出256组特征的数据,第一张图直接用3x3卷积实现,需要192 × 256×3×3×32×32=452984832次乘法;第二张图先用1x1的卷积降到96个特征,再用3x3卷积恢复出256组特征,需要192×96×1×1×32×32+96×256×3×3×32×32=245366784次乘法,使用1x1卷积降维的方法节省了一半的计算量。
参考1:https://zhuanlan.zhihu.com/p/32702031
参考2:https://www.bilibili.com/video/BV1b5411g7Xo
# GoogLeNet
由Inception模块组成的网络称为GoogLeNet,为便于简洁了解网络架构,使用参考2资料的示意图,如下图所示。
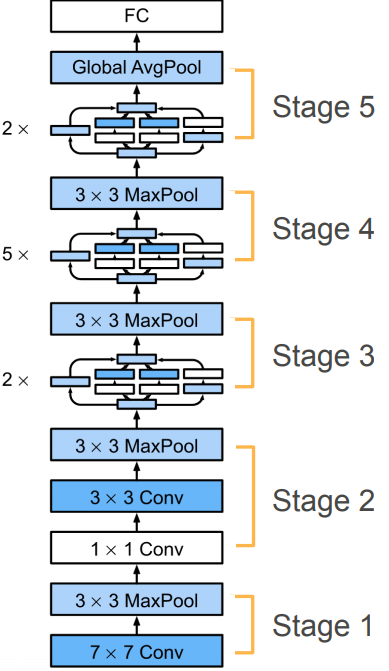
GoogLeNet(Inception V1)分为5个阶段:
在第1和2阶段使用常规的卷积层和池化层堆叠,主要用于缩小输入图像的尺寸和增大特征的维数。-
在第3阶段连续使用2个Inception模块,然后是3×3的最大池化。
在第4阶段连续使用5个Inception模块,同样是3×3的最大池化。
在第5阶段连续使用2个Inception模块,对输出特征图进行全局平均池化,每一个通道代表每一类,例如1000×3×3的特征图,全局平均池化得到1000×1×1,拉直为(1000,)然后softmax分类。全局平均池化的想法来自NIN,主要是用于来替代全连接层,减少参数。但是在实际上最后还是加一个全连接层,方便迁移到其他分类任务。
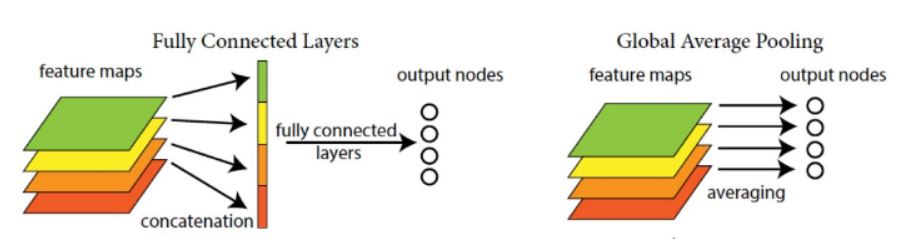
参考3:https://www.cnblogs.com/ywheunji/p/10476719.html
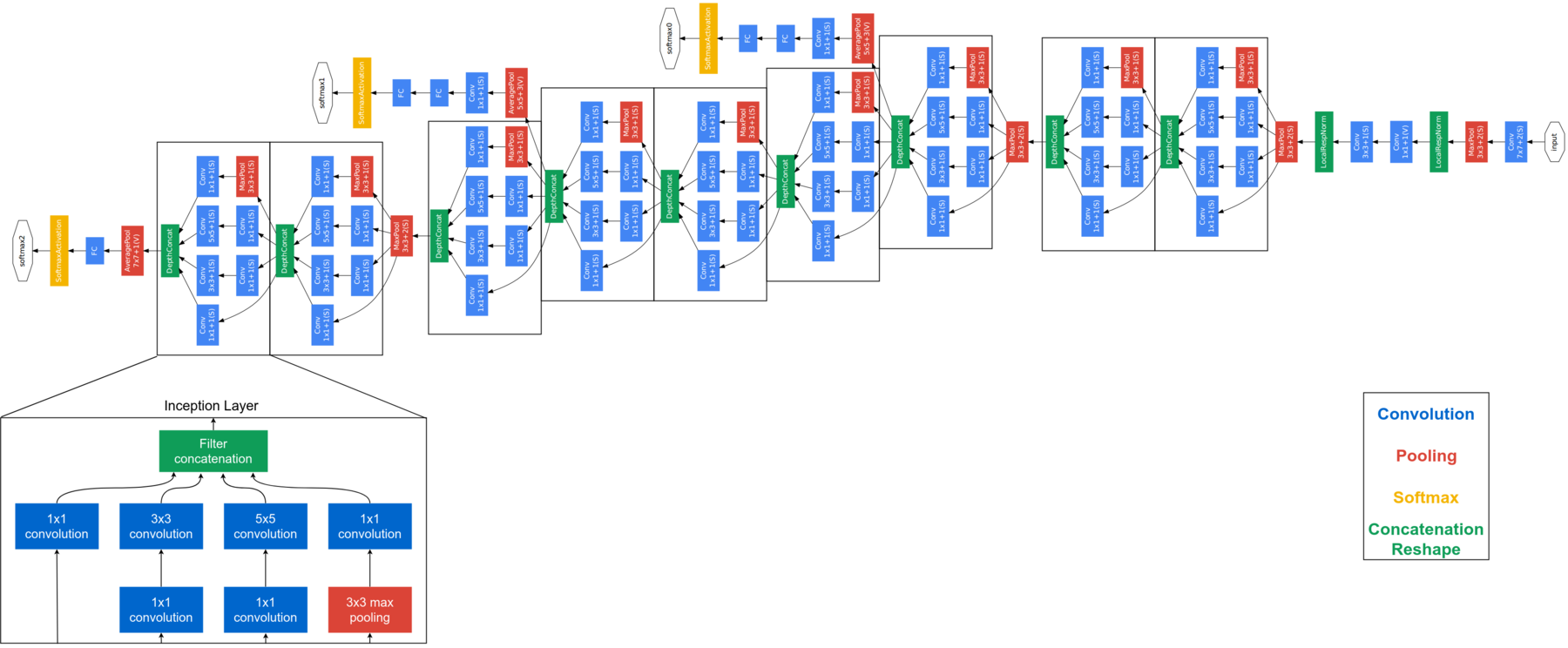
下图为更为清晰的网络结构图,文献中为避免梯度消失,给网络额外增加2个辅助的softmax分类器,在两个辅助分类器的loss上分别增加衰减权重(0.3)。
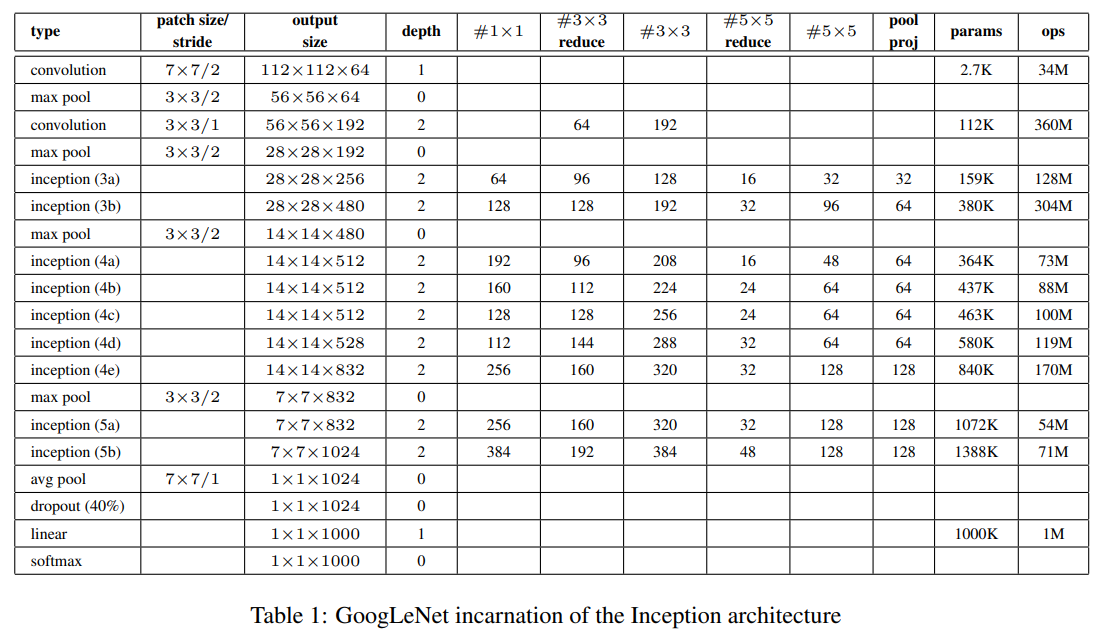
下表为文献中对网络各层的参数的详细说明,#3×3 reduce和#5×5 reduce表示在3×3和5×5卷积之前,用于降维使用的1×1卷积的数量。
# 训练细节
oogLeNet网络使用DistBelief分布式机器学习系统进行训练,训练使用异步随机梯度下降,动量参数为0.9,固定的学习率计划(每8次遍历下降学习率4%)。
# 实验分析
# ILSVRC 2014分类挑战竞赛
ILSVRC 2014分类挑战竞赛的任务是将图像分类到ImageNet的1000子类,其训练集大约有120万张,验证集5万张,测试集10万张。通过性能评估采用top-1和top-5准确率,分别代表实际类别和第一预测类别比例,和实际类别与前五预测类别比例,即如果图像实际类别在top-5中,则认为图像分类正确。挑战赛使用top-5错误率来进行排名。
作者在测试过程中采用一些技巧,分别是:
独立训练7个版本相同的GoogLeNet模型,利用它们进行整体预测。
采用多裁剪预测,具体裁剪方法将图像归一化为四个尺度,分别为256,288,320和352。取这些归一化的图像的左,中,右方块,对于每个方块,将采用4个角以及中心224×224裁剪图像以及方块尺寸归一化为224×224,以及它们的镜像版本。最终每张图像会得到4×3×6×2 = 144的裁剪图像。
多裁剪预测参考:https://www.zhihu.com/question/270988169
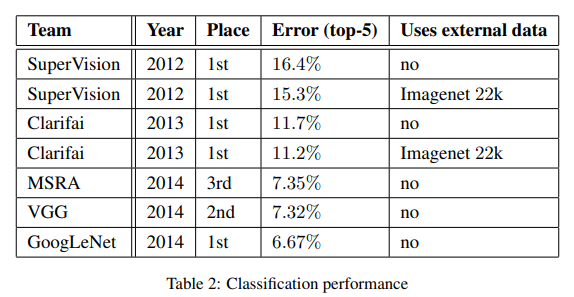
在竞赛中GoogLeNet最终在测试集上取得了top-5 6.67%的错误率,排名第一,具体如下表所示。
# ILSVRC 2014检测挑战竞赛
ISVRC 2014检测任务是在200个可能的类别中生存图像中目标的边界框,如果检测到对象匹配的实际类别正确,且它们的边界框重叠至少50%,则认定检测对象正确。通常性能评估使用平均精度均值(mAP)。GoogLeNet检测采用的方法类似于R-CNN,使用Inception模型作为区域分类器。此外为了提高目标边界框召回率,通过选择搜索方法和多箱预测相结合改进区域生成。
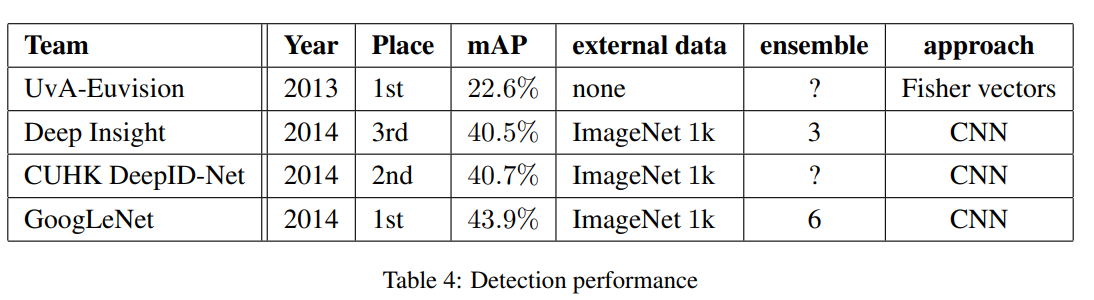
在竞赛中6个GoogLeNet的组合模型,取得了43.9%的mAP,排名第一,具体如下表所示。
# 总结与展望
# 总结
该篇文献基于稀疏连接原理,通过易实现的密集构造块(Inception模块)来近似期望的最优稀疏结果,并在实验中取得可靠的成功,证实Inception模块是改善卷积神经网络一种可行方案。Inception模块的主要创新点有两个:一是使用1×1卷积来降维,减少计算量;二是在同一层采用多个卷积再聚合,实现在多个尺度上的特征融合。
# 展望
对Inception模块进一步改进,包括创建更稀疏更精细的结构、Batch Normalization引入和残存连接等。这也是未来提出的InceptionV2、V3和V4。目前常用的是InceptionV3。
论文:Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., ... & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).