MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications
# 研究背景
随着卷积神经网络在计算机视觉的普遍流行,越来越多不同变种的卷积神经网络出现,一般这些网络的设计都是以深度和复杂性为核心,以获取更好的准确率,在实际应用中,例如人脸识别、自动驾驶和增强现实等任务中,对于网络的实时性有较高的要求。因此也有部分学者开始研究轻量级网络模型,以稍微降低准确率为代价,减少网络的尺寸,提高网络的运算时效性,以便能支持在移动和嵌入式设备上运行。
# 问题描述
经典的卷积神经网络模型,诸如VGGNet、GoogLeNet、ResNet和DenseNet等,这些网络在设计上主要是强调准确率,而忽视了实时性,导致它们只能在科学研究中应用,而无法在工业生产上落实。因此该篇文献以实时性为主要目的,设计一种可在移动和嵌入式设备上应用的网络模型,形象地称为MobileNets。MobileNets是基于深度可分离卷积构建的轻量级神经网络,同时引入两个简单的超参数,来控制网络的规模。在各项实验中表明,它在不牺牲太多准确率的情况下,大大提高了实时性。
# 解决方案
# 深度可分离卷积
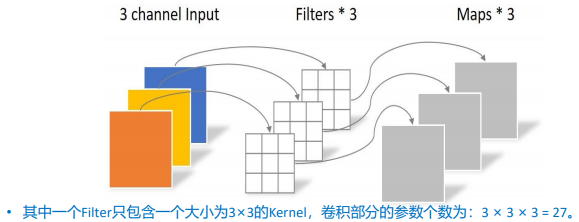
MobileNets的卷积采用的是深度可分离卷积。深度可分离卷积是一种分解卷积的形式,它将标准卷积分解为深度卷积(Depthwise)和点卷积(Pointwise)。这种分解能极大地减少计算和模型参数的大小,下面对比标准卷积和深度可分离卷积的计算量。
对于标准卷积来说,其计算量成本和参数量分别为:
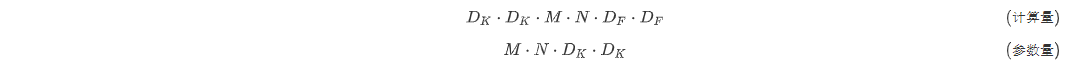
其中M是输入通道数,N是输出通道数,是卷积核大小,是特征图大小。
深度可分离卷积由两层组成:深度卷积和点卷积。
Depthwise(DW)
DW负责通道卷积,一个通道只被一个卷积核卷积。深度卷积的计算成本和参数量为:
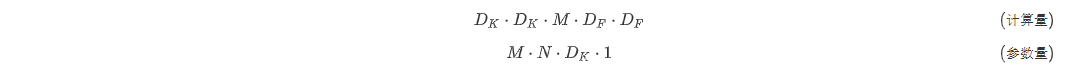
其中M是输入通道数,N是输出通道数,是卷积核大小,是特征图大小。
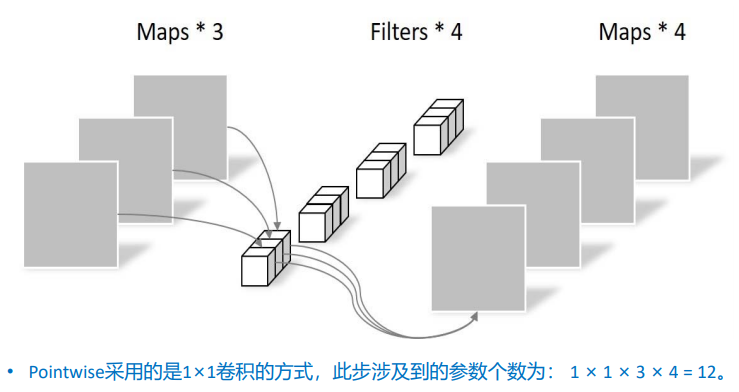
Pointwise(PW)
PW采用M个1×1卷积,来创建深度层的线性组合。点卷积的计算量和参数量为:
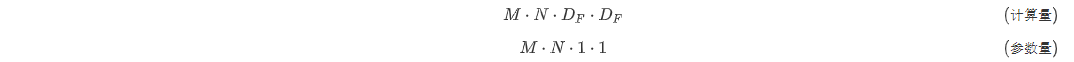
其中M是输入通道数,N是输出通道数,是特征图大小。
因此深度分离卷积的总计算成本和参数量为:
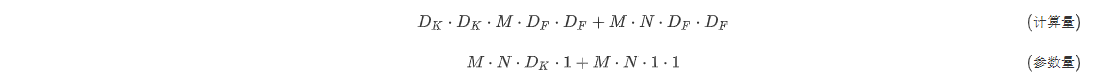
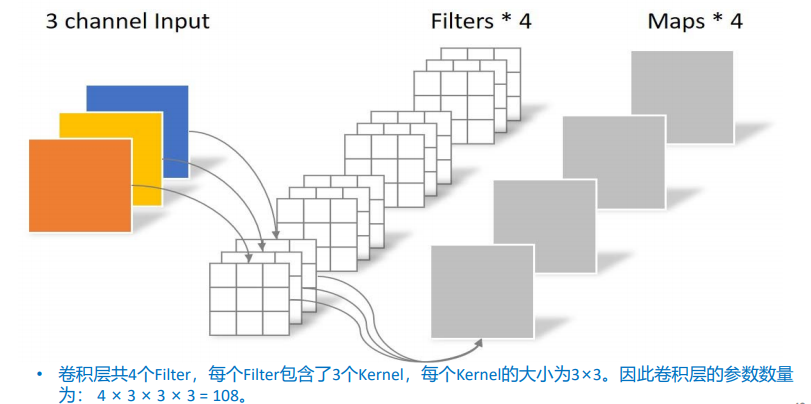
通过标准卷积和深度可分离卷积对比,在实例中标准卷积的参数为108,深度可分离卷积参数为,大大减少了参数量,同时在计算量上也减少了。
特点:DW负责控制卷积特征提取,PW负责控制输出特征维度。
优势:相比于传统的卷积,深度可分离卷积参数量大幅降低,使得深层网络更具有可行性。
# 宽度因子
尽管采用深度可分离卷积的MobileNets已经足够小且延迟低,但是在很多应用条件下可能依然会要求模型变得更小,响应速度更快。因此该篇文献又引入了一个宽度因子的超参数,来控制网络每一层的特征图的通道数(网络均匀变薄)。
在有宽度乘数的深度可分离卷积的计算成本为:
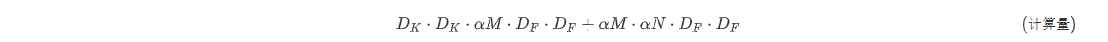
其中$ \alpha \in( 0,1],典型设置为1、0.75、0.5和0.25。 \alpha= 1是基准MobileNet, \alpha < 1$是减少的MobileNets。
# 分辨率因子
减少网络的计算成本的第二个超参数是分辨率因子,用来减少网络每一层的特征图的大小(网络内部表示)。
在有宽度乘数和分辨率因子的深度可分离卷积的计算成本为:
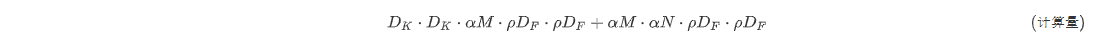
其中\rho \in (0,1]通常是隐式设置的,因此网络的输入分辨率为224、192、160或128。是基准MobileNet,而是简化的计算MobileNets。
# 网络结构和训练细节
下表1定义了MobileNets的基础结构,一共有28层。
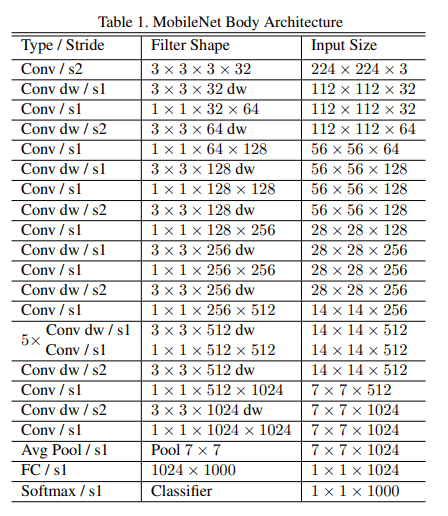
所有层后面都带有一个BatchNorm和ReLU(最后一个全连接除外),下采样是通过跨步卷积实现,接着采用全局平均池化来拉直向量,最终经过全连接和softmax层进行分类。

MobileNet将其95%的计算时间花费在1×1卷积中,其中也包含75%的参数。几乎所有其他参数都位于完全连接的层中。
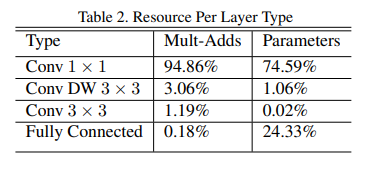
在训练过程中采用RMSprop优化,由于模型较小过拟合现象也会较小,因此使用较小的正则化和数据增强技术。
# 实验分析
# 标准卷积和深度可分离模型对比
采用标准卷积和深度可分离卷积构建相同结构的卷积神经网络,来ImageNet上分类结果对比,如下表所示。
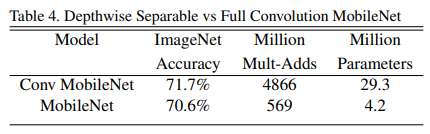
可以看到与标准卷积相比,基于深度可分离卷积构建的MobileNet只在精度上降低了1%,但是计算量和参数量降低了一个数量级。
# 模型收缩超参数对比
- 使用不同的宽度因子来缩小网络结构,其变化如下表所示。
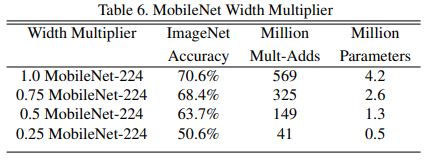
可以看到随着宽度因子的缩小,精度会平稳下降,大致20%之内。
- 使用不同的分辨率因子来缩小网络结构,其变化如下表所示。
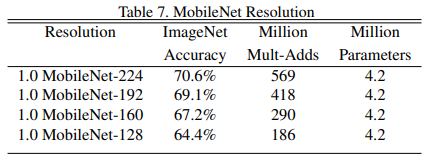
可以看到随着分辨率的缩小,精度也会一定程度下降,大致5%之内。
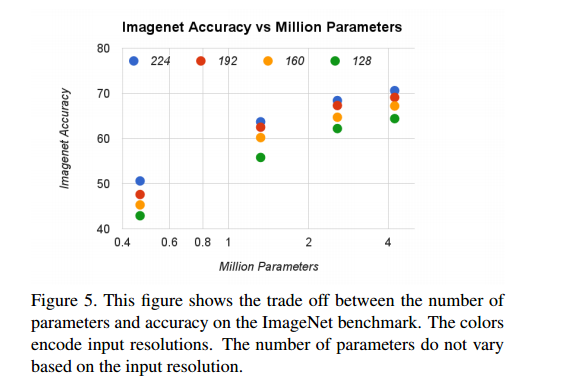
使用宽度因子 $ \alpha \in { 1,0.75,0.5,0.25 }与分辨率 {224,192,160,128 }$的叉积制成的16个模型,其计算量和参数量的变化如下图所示。
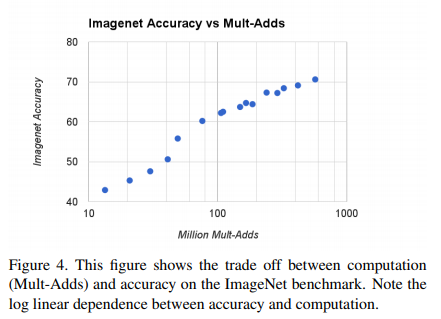
# 主流模型的对比
将完整的MobileNets与原始的GoogLeNet和VGG16进行比较,如下图所示。
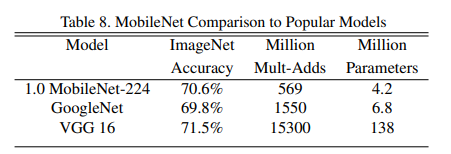
MobileNets的准确度几乎与VGG16一样,但是参数量小32倍,计算量小27倍。它比GoogLeNet更准确,但体积更小,计算量更少。
将减少后的MobileNet(宽度因子和降低后的分辨率160×160)与AlexNet和Squeezenet进行比较,如下图所示。
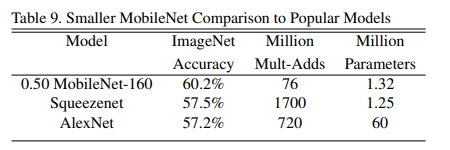
减少后的MobileNet比AlexNet好4%,而计算量却比AlexNet小45倍,少9.4 倍。在大约相同的大小和22倍以下的计算量下,它也比Squeezenet好4%。
# 精细分类
将不同变种的MobileNets在Stanford Dogs dataset进行训练和测试,首先从网络上收集了大规模的嘈杂的训练集来预训练细粒度的狗识别模型,然后在斯坦福狗训练集中对模型进行微调,在Stanford Dogs测试集的结果如下表所示。
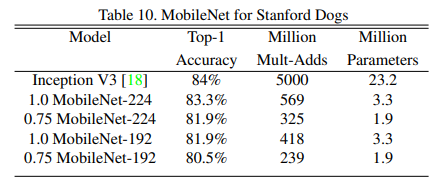
可以看到与Inception V3相比有几乎相同的精度,但是其计算量和参数大大减少。
# 大规模地理定位
PlaNet是做大规模地理分类任务,该任务是确定照片在哪里被分类。该篇文献使用MobileNet的框架重新设计了PlaNet,将其与基于Inception V3架构的PlaNet相对比,在各个数据集上测试如下表所示。
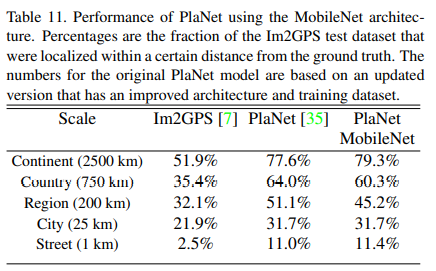
可以看到相比之际,基于MobileNet的PlaNet,在仅有1300W参数的情况下,与基于Inception V3的PlaNet(5200万参数),性能只是稍微降低。
# 目标检测
在Faster-RCNN和SSD框架下,将MobileNet、VGGInception V3进行比较。其中SSD的输入分辨率调整为300,Faster-RCNN分别为300和600,结果如下表所示。
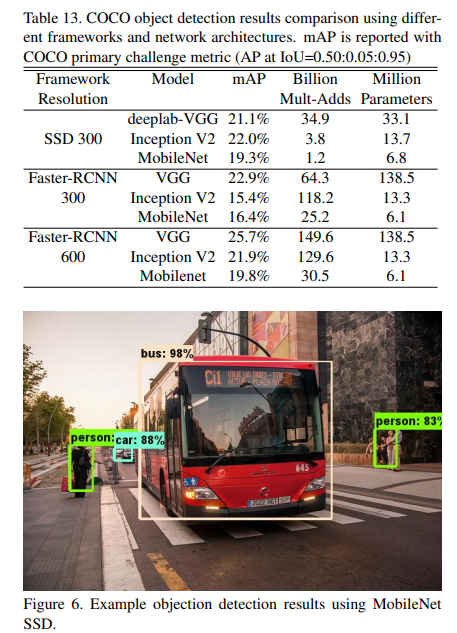
与其他网络架构下的目标检测相比较,MobileNets在精度上相差不大,但是其计算量和参数量有效降低。
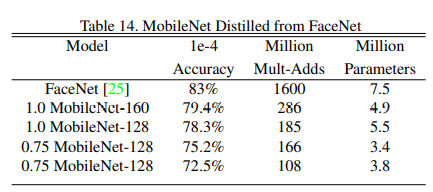
# 人脸识别
FaceNet 是现阶段最先进的人脸识别模型,它基于三重态损失(tripleloss)构建面部嵌入。了建立移动FaceNet模型,使用蒸馏来通过最小化 FaceNet和MobileNet在训练数据上的输出的平方差来进行训练。 基于MobileNet和蒸馏技术训练出结果如下。
# 总结
该篇文献提出一种基于深度可分离卷积的网络模型,称为MobileNets,并通过一系列的实验对比,可以看到MobileNets在精度上与主流的模型差不多,但是其计算量和参数量大幅度的减少。这为在移动和嵌入式设备上,搭载轻量级网络模型提供一个参考。
论文:Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., ... & Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.