树
# 树的基本概念
队列、栈、数组和链表都是线性存储结构,树则是一种非线性存储结构,一般称为树存储结构。
树结构通常用来存储逻辑关系为"一对多"的数据,例如:
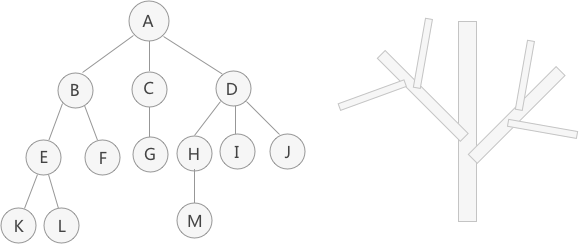
这些元素具有的就是 "一对多" 的逻辑关系,例如元素 A 同时和 B、C、D 有关系,元素 D 同时和 A、H、I、J 有关系等。 观察这些元素之间的逻辑关系会发现,它们整体上很像一棵倒着的树倒过来,这也是将存储它们的结构起名为“树”(或者 "树形")的原因。
存储具有“一对多”逻辑关系的数据,数据结构推荐使用树存储结构。
# 树相关的术语
结点
树存储结构中将存储的各个元素称为“结点”。对于树中某些特殊位置的结点,还可以进行更细致的划分,比如:
- 父节点、孩子节点和兄弟节点:以结点 A、B、C、D 为例,A 是 B、C、D 结点的父结点(也称为“双亲结点”),而 B、C、D 都是 A 结点的孩子结点(也称“子结点”)。对于 B、C、D 来说,它们都有相同的父结点,所以它们互为兄弟结点;
- 树根结点(简称 "根结点" ):特指树中没有双亲(父亲)的结点,一棵树有且仅有一个根结点。例如图中,结点 A 就是整棵树的根结点;
- 叶子结点(简称 "叶结点" ):特指树中没有孩子的结点,一棵树可以有多个叶子结点。例如图 中,结点 K、L、F、G、M、I、J 都是叶子结点。
子树
A 是整棵树的根结点。但如果单看结点 B、E、F、K、L 组成的部分来说,它们也组成了一棵树,结
点 B 是这棵树的根结点。通常,我们将一棵树中几个结点构成的“小树”称为这棵树的“子树”
知道了子树的概念后,树也可以这样定义:树是由根结点和若干棵子树构成的。例如,这棵树就是
由结点 A 和分别以 B、C、D 为根节点的子树构成。
注意:单个结点也可以看作是一棵树,该结点即为根结点。例如图 1a) 中,结点 K、L、F 各自就可以看作是一棵树,只不过树中只有一个根节点而已。
结点的度
一个结点拥有子树的个数,就称为该结点的度(Degree)。例如图中,根结点 A 有 3 个子
树,它们的根节点分别是 B、C、D,因此结点 A 的度为 3。
比较一棵树中所有结点的度,最大的度即为整棵树的度。比如图中,所有结点中最大的度为
3,所以整棵树的度就是 3。
结点的层次
从一棵树的树根开始,树根所在层为第一层,根的孩子结点所在的层为第二层,以此类推。
对于这棵树来说,A 结点在第一层,B、C、D 为第二层,E、F、G、H、I、J 在第三层,K、、L、M 在第四层。
树种结点层次的最大值,称为这棵树的深度或者高度,例如这颗树
有序树和无序树
如果一棵树中,各个结点左子树和右子树的位置不能交换,那么这棵树就称为有序树。反之,如果
树中结点的左、右子树可以互换,那么这棵树就是一棵无序树。
在有序树中,结点最左边的子树称为 "第一个孩子",最右边的称为 "最后一个孩子"。拿图 1 这棵
树来说,如果它是一棵有序树,那么以结点 B 为根结点的子树为整棵树的第一个孩子,以结点 D 为
根结点的子树为整棵树的最后一个孩子。
森林
由 m(m >= 0)个互不相交的树组成的集合就称为森林。比如图1中除去 A 结点,那么分别以 B、C、D 为根结点的三棵子树就可以称为森林。
空树
空树指的是没有任何结点的树,连根结点都没有。
# 二叉树
# 二叉树定义
简单理解,当满足以下两个条件的树就是二叉树:
- 本身是有序树
- 树中包含的各个节点的度不能超过2,即只能是0、1或者2.
例如,1a) 就是一棵二叉树,而图 1b) 则不是。
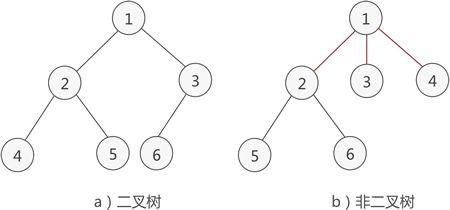
# 二叉树的性质和分类
- 二叉树中,第层最多有个结点。
- 如果二叉树的深度为K,那么二叉树最多有个结点。
- 二叉树中,叶子结点数为,度为2的结点数位,则
二叉树还可以继续分类,衍生出满二叉树和完全二叉树。
满二叉树
如果二叉树中除了叶子结点,每个结点的度都为 2,则此二叉树称为满二叉树。
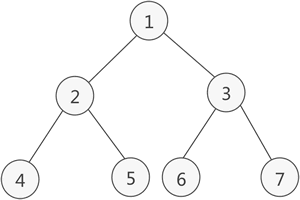
满二叉树除了满足普通二叉树的性质,还具有以下性质:
- 满二叉树中第 i 层的节点数为 个。
- 深度为 k 的满二叉树必有个节点 ,叶子数为。
- 满二叉树中不存在度为 1 的节点,每一个分支点中都两棵深度相同的子树,且叶子节点都在最底层。
- 具有 n 个节点的满二叉树的深度为 。
完全二叉树
如果二叉树中除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树。
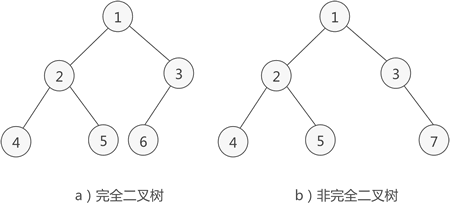
# 二叉树的链式存储结构
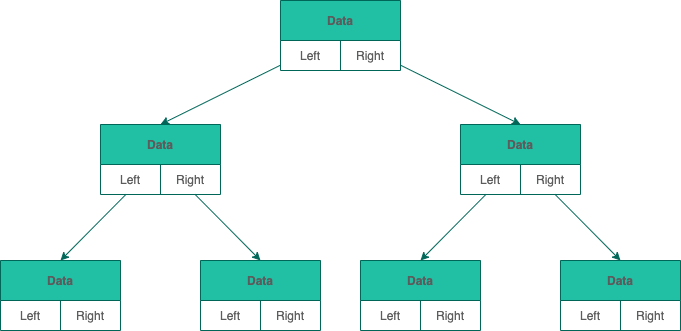
和链表类似,二叉树的链式存储依靠指针将各个节点串联起来,不需要连续的存储空间。
每个节点包括三个属性:
- 数据 data。data 不一定是单一的数据,根据不同情况,可以是多个具有不同类型的数据。
- 左节点指针 left
- 右节点指针 right。
# 二叉树的顺序存储结构
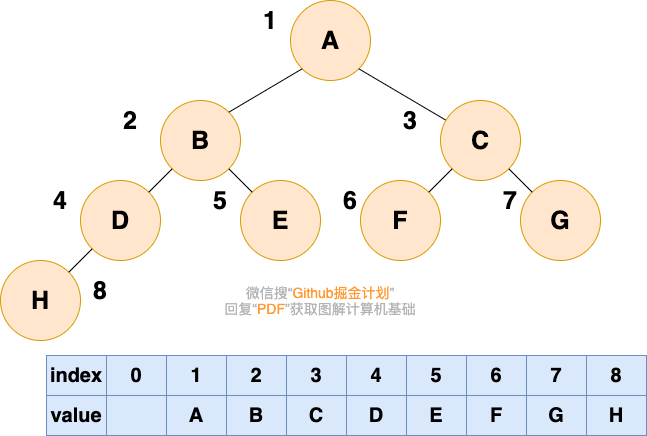
顺序存储就是利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,
子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标
为 i 的位置,那么它的左子节点就存储在 2i 的位置,它的右子节点存储在下标为 2i+1 的位置。
一棵完全二叉树的数组顺序存储如下图所示:
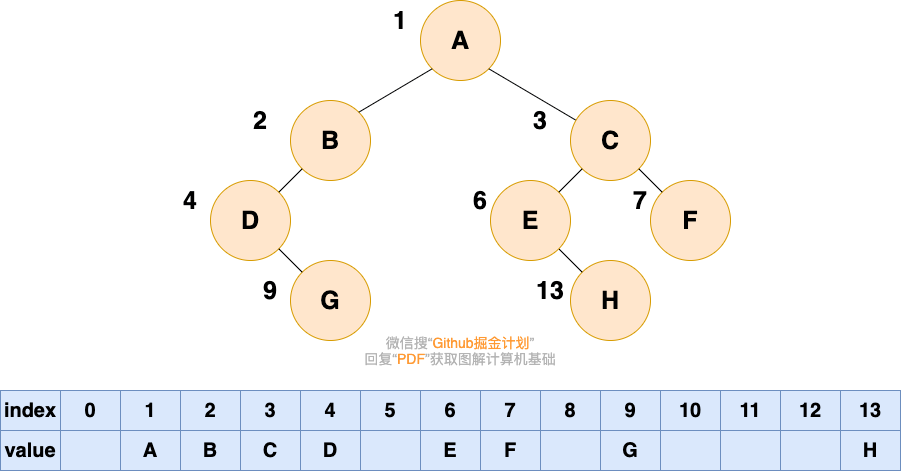
如果我们要存储的二叉树不是完全二叉树,在数组中就会出现空隙,导致内存利用率降低。
# 二叉树的构建-数组存储到二叉树
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(int x, TreeNode left, TreeNode right){
this.val = x;
this.left = left;
this.right = right;
}
public TreeNode(int x) {
this.val = x;
}
public TreeNode() {
}
@Override
public String toString() {
return "[" + val + "]";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class BinaryTree {
public TreeNode root = null;
public BinaryTree(int[] array, int index){
root = createBinaryTree(array, index);
}
public TreeNode createBinaryTree(int[] array, int index){
TreeNode treeNode = null;
if(index < array.length){
treeNode = new TreeNode(array[index]);
/**
* 对于顺序存储的完全二叉树,若根结点序号为0,当某个节点的索引为index,
* 其对应的左子树的索引为2*index+1,右子树为2*index+2
**/
treeNode.left = createBinaryTree(array, 2 * index + 1);
treeNode.right = createBinaryTree(array, 2 * index + 2);
}
return treeNode;
}
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6,7,8,9};
BinaryTree bt = new BinaryTree(arr, 0);
System.out.println(bt.root);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 二叉树的先序遍历
根节点→左子树→右子树
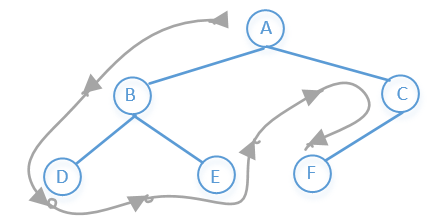
所以上图前序遍历的结果是:A→B→D→E→C→F。
// 先序遍历(递归写法)
public static void preOrder(TreeNode node) {
if(node == null)
return;
System.out.println(node);
preOrder(node.left);
preOrder(node.right);
}
2
3
4
5
6
7
8
9
# 二叉树的中序遍历
左子树→根节点→右子树
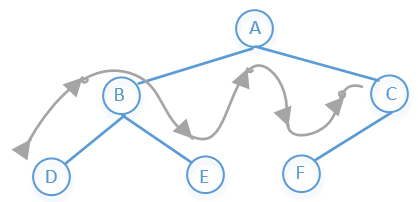
所以上图前序遍历的结果是:D→B→E→A→F→C
// 中序遍历(递归写法) 左根右
public static void inOrder(TreeNode node){
if(node == null)
return;
inOrder(node.left);
System.out.println(node);
inOrder(node.right);
}
2
3
4
5
6
7
8
# 二叉树的后续遍历
左子树→右子树→根节点
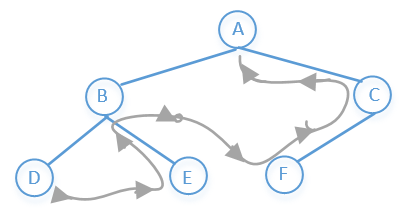
所以上图前序遍历的结果是:D→E→B→F→C→A
// 后序遍历(递归写法) 左右根
public static void postOrder(TreeNode node){
if(node == null)
return;
postOrder(node.left);
postOrder(node.right);
System.out.println(node);
}
2
3
4
5
6
7
8
# 二叉树的层次遍历
# 广度优先搜索(BFS)
先访问上一层,在访问下一层,一层一层的往下访问。
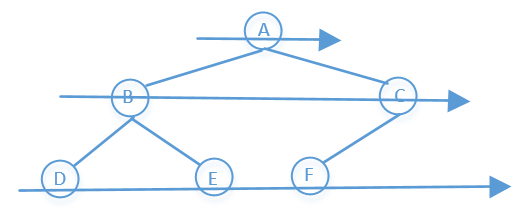
所以上图前序遍历的结果是:A→B→C→D→E→F
// 广度优先搜索(DFS)
public static void levelOrder(TreeNode node){
if(node == null)
return;
//链表,这里我们可以把它看做队列
LinkedList<TreeNode> list = new LinkedList<>();
list.add(node); // 相当于把数据加入到队列尾部
while(!list.isEmpty()){
TreeNode curNode = list.poll();
System.out.println(curNode);
if(curNode.left != null)
list.add(curNode.left);
if(curNode.right != null)
list.add(curNode.right);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 深度优先搜索(DFS)
先访根节点,然后左结点,一直往下,直到最左结点没有子节点的时候然后往上退一步到父节点,然后
父节点的右子节点在重复上面步骤……
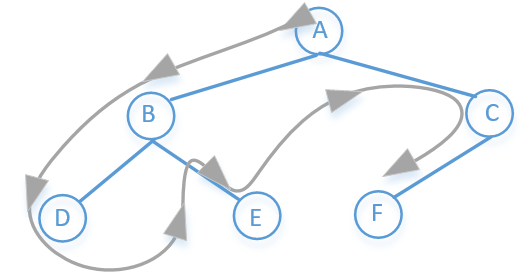
所以上图前序遍历的结果是:A→B→D→E→C→F
// 深度优先搜索(DFS)
public static void treeDFS(TreeNode node){
if(node == null)
return;
System.out.println(node);
preOrder(node.left);
preOrder(node.right);
}
2
3
4
5
6
7
8
# 红黑树
红黑树特点 :
- 每个节点非红即黑;
- 根节点总是黑色的;
- 每个叶子节点都是黑色的空节点(NIL节点);
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
红黑树的应用 :TreeMap、TreeSet以及JDK1.8的HashMap底层都用到了红黑树。
为什么要用红黑树? 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 漫画:什么是红黑树? (opens new window)(也介绍到了二叉查找树,非常推荐)
相关阅读 :《红黑树深入剖析及Java实现》 (opens new window)(美团点评技术团队)
# 参考
http://data.biancheng.net/tree/
https://javaguide.cn/cs-basics/data-structure/tree.html
https://javaguide.cn/cs-basics/data-structure/red-black-tree.html